Filebeat - Lightweight shipper for logs
Filebeat는 경량화된 로그 수집기로 보안 장치, 클라우드, 컨테이너, 호스트 또는 OT 등에서도 수집이 가능합니다. 컨테이너 및 클라우드 환경에서도 실행되기 때문에 Kubernetes, Docker, 클라우드 배포에서 Filebeat를 배포하고 사용할 수 있다. 로그를 1 Line씩 읽고 전달하며, 시스템이 중단되더라도 마지막 중단점을 기억해 재가동시 이어서 전달을 시작한다.
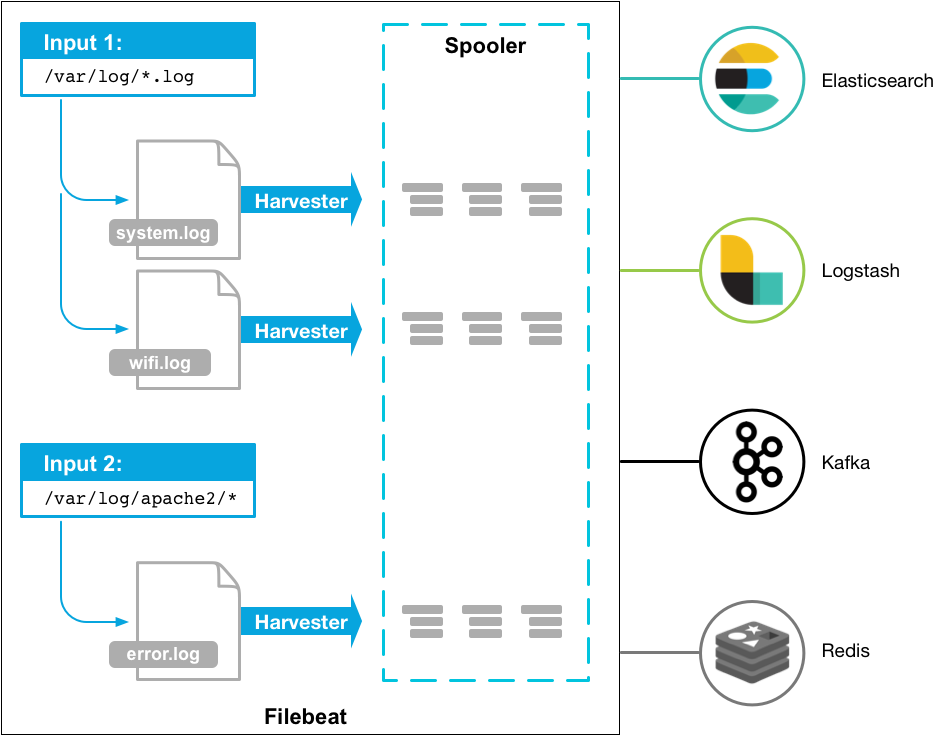
Filebeat는 Input, Harvester, Spooler 라는 3가지 주요 구성요소를 갖는다.
Input은 데이터 소스를 찾고 harvester를 통제한다. 데이터 소스 경로에서 설정된 type 및 정보와 일치하는 파일을 찾고 그 파일을 읽기 위해 harvester를 실행한다.
하나의 Harvester는 하나의 파일을 담당하고 데이터 파일을 열고 닫으며 로그 데이터를 1 Line 단위로 읽는다. 즉, 읽을 데이터 파일이 많다면 그에 따라 harvester의 개수도 많아진다.
spooler는 harvestor가 읽은 로그 데이터를 집계하고 연결된 목적지로 전달한다.
harverster가 실행중일 떄는 file descriptor도 켜져있다. 파일이 수확되고 있는 도중에 위치가 변경되거나 이름이 변경되더라도 파일비트는 계속해서 파일을 읽는다. 이로 인해 harvester가 닫힐때까지 디스크 공간이 점유되는 부작용도 존재한다. 기본 설정으로, 파일비트는 close_inactive에 도달할 때까지 파일을 열고 있다.
- harvester가 종료된 동안 파일이 이동하거나 삭제될 경우 파일 수확이 계속되지 않을 것이다.
- 파일 수확은
scan_frequency가 경과한 후에만 시작될 것이다. - 만약 harvester가 아직 파일을 읽고 있는데 파일이 삭제된다면 file handler가 닫히면서 근본 리소스가 해제될 것이다.
Filebeat는 다수의 Input과 Harvester로 구성된다. Input 대상이 되는 파일을 어디까지 읽었는지, 어디까지 전송했는지에 대한 정보는 Harvester의 offset에 주기적으로 저장되며 이는 registry 파일에서 관리된다. elasticsearch, logstash, 카프카, 레디스 등 output 미들웨어 시스템에 문제가 발생하면, filebeat는 마지막으로 보낸 행을 기록하고, 문제가 해결될때까지 계속 데이터를 수집한다. 이러한 관리 덕에 filebeat를 정지하고 실행해도 데이터의 위치를 기억한 상태로 기동된다. Harvester는 데이터를 output에 연결된 목적지로 보낸 후에 데이터를 잘 받았다는 응답을 기다리는데, 해당 응답을 받지 못할 경우 다시 데이터를 보내게됨으로써 반드시 한번은 손실없이 데이터를 보낼 수 있다.
특징
- BackPressure-sensitive 프로토콜 : 연결된 Logstash 또는 Elasticsearch의 데이터 처리 속도에 맞춰 Filebeat의 읽기 속도를 조절함
- Autodiscover : 자동 검색을 통해 새로운 컨테이너를 감지하고 적합한 Filebeat 모듈을 통해 동적으로 컨테이너를 모니터링함
-
filebeat는 inode를 저장해 파일을 식별한다. 그러므로 inode를 조작하면 파일이 이미 처리되었는지 여부를 알기 어렵다.
-
filebeat는 전송한 파일에 대해 내부적으로 offset 정보를 저장하기 때문에 중간에 crash(장애, 통신지연 등)가 발생해도 이어서 전송이 가능하다. (디버그 모드로 실행시 offset확인 가능 $ filebeat -c filebeat.yml -e -d "*")
- 거의 실시간으로 새 로그 행을 읽을 수 있도록 파일 핸들러를 열어두기 때문에 많은 수의 파일을 수집하는 경우, 열려있는 파일 수가 문제가 될 수 있다. registry_file에 각 파일의 상태를 유지하고 파일 상태를 통해 filebeat가 다시 시작될때 이전 위치에서 파일 읽기를 계속할 수 있다. 만약 많은 수의 새 파일이 생성되면 registry_file의 크기가 너무 커질 수 있다. 크기를 줄이기 위해 clean_removed와 clean_inactive 구성 옵션을 사용할 수 있다.
- filebeat는 개행 문자를 사용해 이벤트의 끝을 감지하기 때문에 수집 중인 파일의 끝에 개행이 없을 경우 마지막 행을 읽지 않으므로 주의한다.
- filebeat의 cpu 점유율이 높다면 파일을 너무 자주 검색하도록 설정된 것은 아닌지 filebeat.yml파일의 scan_frequency값을 확인해 1 미만인 경우 조정한다.
Linux OS에서 Filebeat는 inode와 device값을 사용해 파일을 식별한다. 디스크에서 파일을 제거하면 파일 순환에 의해 제거된 inode 값과 동일한 값을 새로 생성된 파일이 할당받을 수 있다. 이 경우에 Filebeat는 registry에 기록된 정보에 의해 동일한 파일로 간주하고 이전 위치에서 읽으려고 시도하기 떄문에 문제가 될 소지가 있다. 기본적으로 registry에 기록된 상태 정보는 절대 제거되지 않기 떄문에 inode 재사용 문제를 해결하려면 clean_* 옵션, 특히 clean_inactive를 사용해 비활성 파일의 상태를 제거하는 것이 좋다. 디스크에서 제거된 파일에 대해서는 clean_removed를 사용할 수 있다. clean_removed는 스캔 중에 파일을 찾을 수 없을 때마다 registry에서 파일 상태를 정리하고, 나중에 동일한 파일이 생성되면 처음부터 다시 전송된다.
Logstash의 output은 @metadata 필드를 자동으로 제거하기 때문에 필드를 보존하고자 할 경우, mutate filter를 사용해 필드의 이름을 변경해주어야 한다.
< Beats 제품군 >
- Filebeat : 로그 파일
- Metricbeat : 메트릭
- Packetbeat : 네트워크 데이터
- Winlogbeat : Windows 이벤트 로그
- Auditbeat : 감사 데이터
- Heartbeat : 가동 시간 모니터링
- Functionbeat : 서버를 사용하지 않는 수집기
이외에도 오픈 소스 Beats들이 존재하며 공통 라이브러리인 libbeat를 기반으로 제작되었습니다. Beats 커뮤니티 목록에서 원하는 기능의 Beats를 확인할 수 있습니다.
ref)
https://yongho1037.tistory.com/709
https://coding-start.tistory.com/187
https://www.elastic.co/guide/en/beats/filebeat/current/how-filebeat-works.html
input은 harvester를 관리하고 모든 소스를 찾는 역할을 한다. 만약 input 타입이 log라면, 정의된 glob 경로에 부합하는 드라이브의 모든 파일을 찾고 각 파일에 대해 harvester를 시작한다.
파일비트는 현재 몇가지 input 타입을 지원한다. 각 input 타입이 여러 번 정의될 수 있다. log input은 각 파일에 대해 harvester가 시작되어야 하는지, 이미 실행 중인지, 그 파일은 무시될 수 있는지 등을 확인한다. harvester가 닫힌 뒤에 파일의 크기가 변했을 경우에만 새로운 lines들이 수집된다.
파일비트가 어떻게 파일의 상태를 기억하는가.
파일비트는 각 파일의 상태를 기억하고 레지스트리 파일에 빈번하게 붓는다. 그 상태는 harvester가 읽던 마지막 offset을 기억하는데 사용되고 log lines이 확실히 보내지는데 사용된다. 만약 Elasticsearch, Logstash와 같은 output이 접근불가능하다면, output이 다시 사용가능하게 되었을 때 곧바로 파일비트가 전송된 마지막 lines을 추적해서 파일을 이어서 읽어들일 것이다. 파일비트가 구동하는 동안에는 각 input에 대한 상태 정보를 기억한다. 파일비트가 재시작될때 레지스트리 파일의 데이터는 상태 정보가 다시 build되는데 사용되고 파일비트는 각 harvester를 마지막으로 알려진 지점에서 이어서 계속한다.
각 input 마다, 파일비트는 파일의 상태를 유지한다. 왜냐하면 파일의 이름이 재설정되거나 위치가 변경될 수 있으므로 파일 이름과 경로는 파일을 확인하는데 충분치 않기 때문이다. 파일비트는 각 파일마다 고유의 식별자를 저장해 이전에 수확된 파일인지 탐지한다.
만약 당신이 매일 많은 수의 파일을 새로 만든다면 레지스트리 파일이 너무 커질지도 모른다. 해당 이슈 해결을 위한 세부 설정들은 Registry file is too large를 보십시오.
파일비트가 어떻게 적어도 한번의 전송을 보증할 수 있는가.
파일비트는 지정된 output으로 데이터 손실없이 적어도한번의 전송을 보증한다. 이것이 가능한 이유는 파일비트가 각 전송작업의 상태를 레지스트리 파일에 저장하기 때문이다.
정의된 output이 막혀서 모든 전송 작업을 확실히 할 수 없는 상황이 오면, 파일비트는 output에서 전송 작업이 완료되었다는 확인이 있을 때까지 계속해서 전송 작업을 시도할 것이다.
만약 전송작업 도중에 파일비트가 멈추면, 멈추기 전에 output이 모든 전송 작업을 인정하도록 기다리지 않는다. 파일비트가 멈추기 전에 output으로 전송되었지만 확인되지 않은 작업은 파일비트가 재시작할때 다시 전송된다. 이로 인해 각 전송 작업은 적어도 1번 제대로 수행될 수 있다. 다만, output으로 전송된 작업을 복제하는 걸로 끝날 수도 있다. shutdown_timeout 옵션을 통해 파일비트가 멈추기 전에 특정 시간을 기다리도록 설정할 수 있다.
파일비트는 log rotation과 오래된 파일 삭제와 관련해서 최소 1회 전송 보증에 대해 한계가 존재한다. 만약 로그 파일이 디스크에 저장되어 파일비트에서 처리하는 것보다 빠른 속도로 rotate 되거나 혹은 output이 이용불가능한 동안 파일이 삭제된다면 데이터가 소실될 수도 있다. Linux에서 파일비트가 inode 재사용의 결과로써 몇 줄을 건너뛸 수 있다. inode 재사용 이슈에 대한 자세한 내용은 Common problems를 보십시오.
Elasticsearch 사용을 위한 mechinsm 설명은 여기까지 하고, 이제 실제 사용을 위한 설치 작업으로 들어가보겠습니다.
1. Filebeat 설치하기
# elasticsearch 설치
$ wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-oss-7.10.2-linux-x86_64.tar.gz
$ tar -zxvf filebeat-oss-7.10.2-linux-x86_64.tar.gz
# 환경 설정 수정 (filebeat 디렉토리에서) - indent주의!!
$ mkdir config
$ vi config/temp.yml
-----------------------------
filebeat.inputs: # 7버전 기점으로 filebeat.prospectors -> filebeat.inputs 변경
- type: log # 6버전 기점으로 input_type -> type 변경 (type에 맞는 확장자 사용)
enabled: true
paths:
- /home/paulmauer/log* # 수집할 log 파일의 경로
tail_files: true # filebeat 시작시점을 기준으로 파일 끝에서부터 로깅을 읽기 시작
ignore_older: 1m # filebeat 시작시점을 기준으로 설정한 시간 이전의 내용은 무시
close_inactive: 2m
clean_inactive: 15m
# filebeat logging 설정
logging.level: info
logging.to_files: true
logging.files:
path: /home/paulmauer/elastic/filebeat-7.10.2-linux-x86_64/logs/
name: filebeat-log
keepfiles: 7
rotateeverybytes: 524288000
# 수집된 데이터를 logstash 전송
output.logstash:
hosts: ["logstash실행서버IP:5044"]
-----------------------------
# filebeat 실행
$ ./filebeat -c config/access_log.yml -d publish & # & : 백그라운드 실행
# filebeat 실행2
$ sudo service filebeat start
$ sudo service filebeat status
$ sudo service logstash start # logstash도 사용. 이러고 다시 conf 파이프라인을 적용해서 실행함. 서비스에 등록되어야 service start 가능하지 않나? 그리고